Cognee 是什麼?想全部自己架、不依賴雲端的 AI 記憶引擎
編輯:BJ最後檢查:2026-06-09主要來源:GitHub
Cognee 是主打「自架、資料不外流」的開源 AI 記憶引擎,預設用內嵌式資料庫,不用架一堆重服務就能跑起知識圖譜。這篇說明 Cognee 能幹嘛、跟 mem0 與 Zep 差在哪、要不要錢、怎麼開始,以及什麼團隊會特別需要它。
Cognee 想解決什麼問題
很多 AI 記憶方案要嘛走雲端、要嘛自架起來要接一堆服務(圖資料庫、向量庫、快取…)。對「資料絕對不能出公司」或「不想維運一堆東西」的團隊,這兩條路都卡。
Cognee 想做的是:一個可以全部在自己機器上跑、又不用架很多重服務的記憶引擎。它把非結構化資料(文件、對話)自動整理成知識圖譜,讓 AI 之後能跨對話記得、也能看出資料之間的關聯。
最大的賣點是自架很輕——預設用 SQLite、LanceDB、Kuzu 這種可以「內嵌」執行的資料庫,不用另外架伺服器,一個 pip install 加一支 API key 就能開始。
它適合誰
適合「資料要落地、又想省維運」的人:
- 在法遵嚴格的產業(醫療、金融、政府),資料不能上雲。
- 有資料落地(data residency)要求,必須全部在自己機房。
- 想要知識圖譜的能力,但不想架一堆重服務。
- 想先在本機用最少設定試「AI 記憶」概念的開發者。
如果你不在意資料上雲、只想最快加記憶,mem0 的雲端方案更省事;如果你要的是「時間軸、查歷史狀態」,那是 Zep 的主場。
它怎麼運作
你把資料餵給 Cognee,它會自動做三件事:
- 把資料切好、抽出裡面的實體和關係。
- 建成一個知識圖譜(誰連到誰、什麼屬於什麼)。
- 存進本機的圖庫和向量庫,之後可以用語意搜尋 + 圖關係一起查。
因為圖庫和向量庫預設都是內嵌式的,整包可以跑在一台機器上,不用先架 Neo4j、Postgres 那種獨立服務。要擴大時再換成比較重的元件。
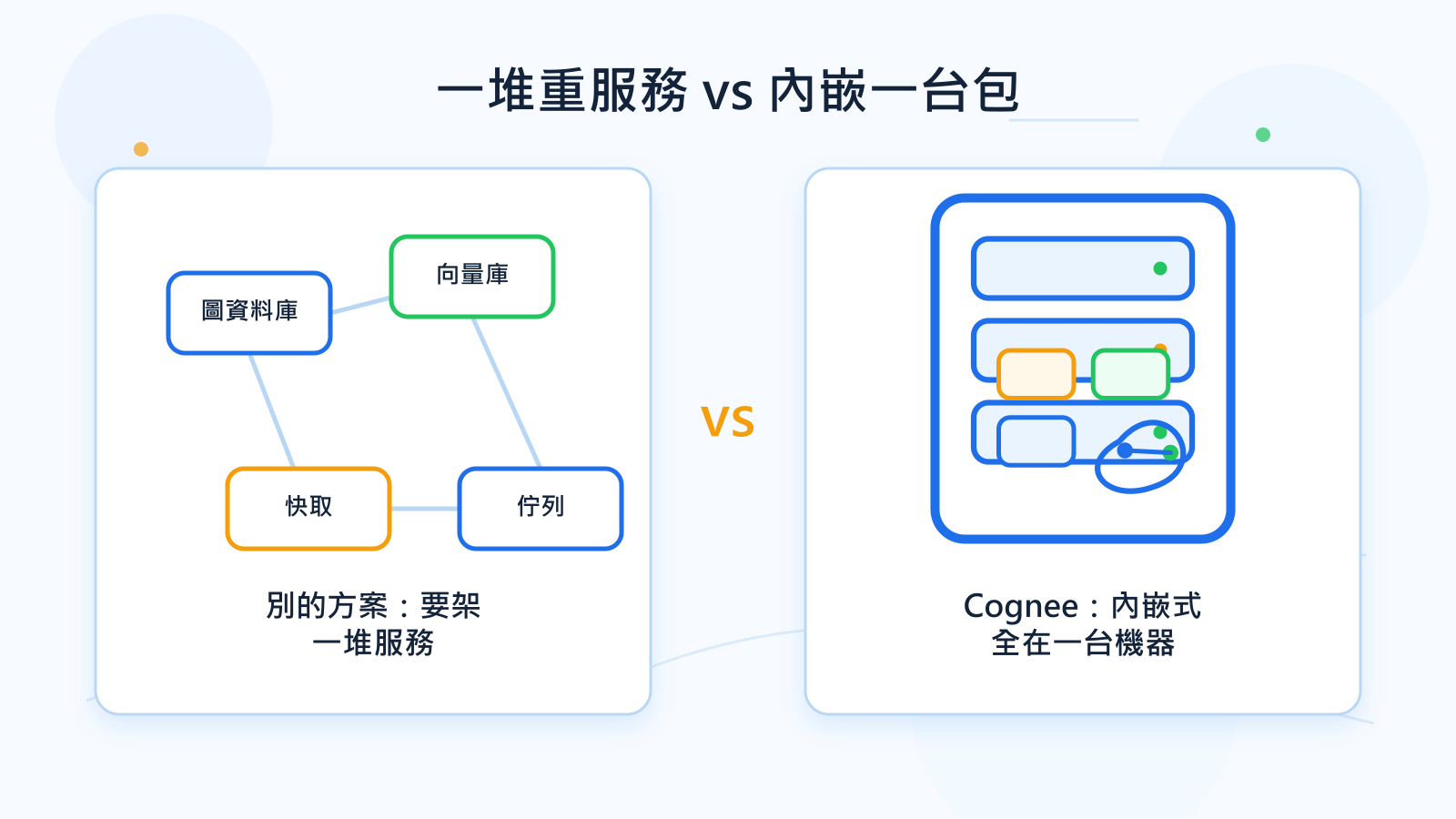
跟 mem0、Zep 差在哪
三個都在做 AI 記憶,但選擇的理由不同:
- [mem0](/articles/github-tools/mem0):最好上手,雲端友善,快速記住使用者偏好。
- [Zep / Graphiti](/articles/github-tools/zep-graphiti-temporal-memory-guide):專攻時間軸,記得住「什麼時候變的」。
- Cognee:專攻全自架、維運輕,資料完全在自己手上。
直接說結論:要雲端方便用 mem0,要時間軸用 Zep,要全部自己掌控用 Cognee。完整比較看這篇。
要不要錢?
- 開源版:Apache 2.0 授權,免費、可自架。這是 Cognee 的主場。
- 官方雲端:也有託管服務,適合不想自己顧基礎設施的團隊。
有個現實要先說:Cognee 建圖譜、查詢時要呼叫 LLM 和 embedding,這部分 API 費用另計。就算全自架,模型呼叫的錢還是要花——除非你連模型都換成本機的。
新手好不好上手?
「安裝」這關 Cognee 算輕鬆——pip install cognee、設一支 LLM API key 就能跑,官方主打「五行程式碼」建記憶。也可以用 Docker 一行起 API server。
但「知識圖譜」這個概念本身有門檻,跟 mem0 那種「存一段文字」比,要多花點時間理解圖譜怎麼建、怎麼查。適合願意寫一點 Python、想掌控資料的人。
最小試法:
pip install cognee,設好 LLM API key。- 餵幾份你熟的文件進去,讓它建圖譜。
- 問幾個你知道答案的問題,看它有沒有抓到文件之間的關聯。
- 確認「全在本機、答得準」,再考慮放進正式流程。
使用上要小心的事
第一,餵進去的資料髒,圖譜就跟著髒。Cognee 是自動幫你抽實體和關係建圖,來源資料亂或抽取設定沒調好,建出來的圖就會連錯,之後查什麼都不準。前期在資料清理上多花點功夫,比事後補救省事。
第二,「自架免費」不等於零成本。就算資料庫是內嵌的,模型呼叫、機器、備份、升級還是你的責任。省的是「不用架很多服務」,不是「完全不用維運」。
第三,自架不等於不用管。會選 Cognee 的人多半就是在意資料落地,那更要把個資的刪除、匯出、授權一開始就設計好——別讓「全在自己機器上」變成「反正在內網、沒人管」。
想開始用 Cognee?
開始前,這樣排最省事:
- 先確認你的關鍵需求是不是「資料一定要落地、要全自架」——如果不是,mem0 更省事。
- 用
pip install cognee在本機餵幾份文件試,看圖譜建得準不準。 - 要正式用,再評估內嵌式 DB 夠不夠、還是要換重一點的元件。
- 上線前把個資治理和記憶修正流程設計好。
如果你的痛點就是「資料不能出公司、又不想架一堆服務」,Cognee 剛好打中;反過來,你不在意上雲的話,其他方案通常更快上手。
下一步可以先看什麼
- mem0 是什麼:雲端友善、最好上手看這個。
- Zep 與 Graphiti 是什麼:要時間軸、查歷史狀態看這個。
- Mem0、Letta、Zep 三個記憶層比較:一次搞懂怎麼選。
參考來源
- Cognee GitHub:https://github.com/topoteretes/cognee
- Cognee 官方網站:https://www.cognee.ai
- Cognee 文件:https://docs.cognee.ai
本文最後查證日期:2026-06-09
延伸閱讀
mem0 是一個給 AI Agent 和 AI 應用使用的記憶層,讓 AI 不只看當下對話,也能記住使用者偏好、歷史互動與任務狀態。本文用白話整理 mem0 可以做什麼、去哪裡用、要不要錢、怎麼開始,以及什麼情境真的需要 AI 長期記憶。
Zep 與 Graphiti 是什麼?讓 AI 記得住「什麼時候變的」Zep 是專攻「時間軸」的 AI 記憶方案,資訊改變時不刪舊的、只標記失效,讓 AI 能回答『使用者以前偏好 A、四月後改成 B』。它的開源核心是 Graphiti。這篇說明 Zep 與 Graphiti 各是什麼、跟 mem0 差在哪、要不要錢、怎麼開始。
AI 的記憶怎麼做?Mem0、Letta、Zep 三個開源記憶層深入比較想讓 AI 記住使用者、不用每次重講背景,就要幫它加一層「記憶」。Mem0、Letta、Zep 是 2026 年最常被用的三個開源 AI 記憶方案,架構完全不同。這篇分別深入介紹三個各自擅長什麼、怎麼開始,最後比較該選哪個、能不能搭在一起用。
Letta 是什麼?做一個會自己記住、會成長的 AI agentLetta 前身是知名研究專案 MemGPT,它把記憶做成 AI agent 的核心零件,讓 agent 能自己讀寫記憶、跨天累積經驗。這篇用新手角度說明 Letta 能幹嘛、跟 mem0 那種記憶外掛差在哪、要不要錢、怎麼開始,以及什麼情境才真的需要它。
Maxun 是什麼?用點選的方式把網站變成表格,不用寫爬蟲Maxun 是開源的 no-code 網頁擷取工具,你在畫面上點一點要哪些欄位,它就把整個網站抓成表格或 API,不用寫程式。這篇用新手角度說明它能幹嘛、適合誰、怎麼開始,以及跟 Firecrawl、Crawl4AI、browser-use 怎麼分。
Crawl4AI 是什麼?免費開源、專門把網頁變成餵 AI 資料的爬蟲Crawl4AI 是 GitHub 上很紅的開源網頁爬蟲,專門把網頁抓下來、轉成乾淨的 Markdown 餵給 AI。這篇用新手角度說明它能幹嘛、跟 Firecrawl 差在哪、要不要錢、什麼人適合用,以及爬網頁前要注意的風險。